앤드류 살티스 저 '실시간 데이터 파이프라인 아키텍처' 를 요약 정리한 글 입니다.

3장 수집 단계에서 데이터 전송 : 데이터 파이프라인 분리
요약
1. 컨슈머 처리 속도나 네트워크 장애 발생에도 데이터 유실 방지를 위해
커메세지 큐를 사용해 수집과 분석 단계를 분리햐고, 메세지를 지속적으로 저장하는 시스템으로 구축야한다.
2. 프로듀서, 메세지 큐, 컨슈머, 요소들 간 네트워크 장애에 대비해 영구 저장소, 응답 확인 등으로 최대한 데이터 유실/중복 방지할 수 있고 복잡도, 처리 속도, 유실/중복 가능성 의 트레이드 오프를 정해 시맨틱 종류 및 설계를 해야한다.
정리 (펼치기)
1. 메세지 큐 단계가 필요한 이유
단일 서버로 구성하면 메세지 큐 불필요.
프로세스간 통신 방법 중 메세지 큐 모델을 선택하면 수집과 분석 단계의 커플링을 끊고 통신 수행 가능.
-> 서로 다른 단계 간에 명시적인 호출 하지 않음으로 디커플링 만족 + 더 높은 수준의 추상화된 시스템으로 구현
2. 메시지 큐
1) 메시지 큐 구성요소 3
프로듀서, 브로커, 컨슈머
브로커 : 여러개 큐들이 모여 운영됨. 프로듀서로부터 받은 메세지를 메시지 큐에 넣고, 읽는다. 컨슈머는 브로커로부터 메세지를 읽는다.
2) 메세지 유실 방지를 위한 아키텍쳐
메세지 큐를 사용한다 -> 수집과 분석단계 분리 가능
컨슈머의 처리 속도가 느릴 수있고, 네트워크 장애 발생 가능
=> 메세지를 지속적으로 저장하는 시스템은 컨슈머의 처리 속도나 연결 장애 발생하더라도 데이터 유실 방지가능.
3) 메세지 전달 시맨틱
(1) 메세지 전달 시맨틱 3
- 최대 한 번 At-most-once : 일부 메세지 유실 가능. 유실된 메세지 컨슈머에게 도달하지 못함
- 적어도 한 번 At-least-once : 메세지 절대 유실 불가. 컨슈머에게 동일 메세지 두 번 이상 처리할 가능
- 정확히 한 번 Exactly-once : 메세지 절대 유실 불가. 컨슈머는 반드시 한 번만 처리
(2) 메세지의 중복이나 유실이 발생 할 수 있는 부분
프로듀서① --- ② ---> 브로커③ --- ⑤ ---> 컨슈머⑥
⭥
메세지 큐 ④① 프로듀서 :
- [메세지 생성 ~ 네트워크 통신을 통해 브로커에게 보내기 직전] 장애 발생 시 데이터 유실
- 브로커와 통신을 통해 정상적으로 보냈지만 브로커로부터 메세지 전달받았다는 응답 받지 못하면, 동일 메세지 한 번 더 브로커에게 전달 될 수 있음
② 프로듀서, 브로커 간 네트워크 통신 :
- [프로듀서 - 브로커간 통신 이슈] 프로듀서는 브로커에게 메세지 보내지 못할수도
- 브로커가 메세지 받아서 저장했지만 완료되었다는 응답 보내지 못한 경우. 동일한 메세지 두 번 전달될 수 있다.
③ 브로커 :
- [브로커] 저장소에 저장하기 직전 메모리에 있던 메세지 유실될 수 있음.
- 프로듀서에게 메세지 전달받았다고 응답 보내기 전에 장애 발생 시 프로듀서는 동일 메세지 두 번 보낼것.
- 브로커 내부에 저장된 커밋(컨슈머가 마지막으로 읽은 위치) 데이터에 장애 발생 시 컨슈머는 동일한 메세지 두 번 이상 데이터 처리할 수도 있음.
④ 메세지 큐 : 저장소에 장애 발생 시 디스크에 저장된 메세지 중 일부 유실될 수도
⑤ 컨슈머, 브로커 간 네트워크 통신 :
- 브로커가 컨슈머로 메세지 보냈음에도 컨슈머는 메세지 받지 못했을 수도
- 컨슈머가 처리한 마지막 메세지 정보 브로커에 전달 안되면 동일한 메세지 두 번 이상 컨슈머에서 처리될 수 있음.
⑥ 컨슈머 :
- 브로커로부터 메세지 전달 받은 후, 데이터 처리 전에 장애 발생 / 커밋 정보 브로커로 전달 못하면 동일 메세지 두 번 이상 처리할 가능성있음.
- 여러 컨슈머가 동일한 메세지 여러 번 읽을 수도.
(3) 시맨틱 종류 선택 시 트레이드 오프
작은 복잡도, 빠른 데이터 처리, 메세지 중복/유실 가능성 높음
VS
높은 복잡도, 느린 데이터 처리, 메세지 중복/유실 가능성 없음
Kafka, ActiveMQ 등은 '정확히 한 번' 지원 안함 -> 프로듀서와 컨슈머 간 통신에서 정확히 한 번 처리지원하도록 메타데이터 제공.
(4) '정확히 한 번' 처리를 위해 고려사항 2
- '② 프로듀서, 브로커 간 네트워크 통신' 에서 메세지 두 번 보내지 말 것.
: 프로듀서가 이전에 보낸 데이터 정상적으로 받았는지 브로커로 요청하고 확인 응답(ack)를 받도록해서 각 메세지에 대한 추적 이루어지게해야 '정확히 한 번' 메세지 전달 가능 - '⑥ 컨슈머' 마지막으로 처리한 메세지의 메타데이터 저장
: 메세지 ID, 오프셋 등 메세징 시스템에 따라 메세지 구분 데이터를 영속 저장소에 저장해 메세지 중복 처리를 방지해야한다. 메타데이터 저장 시 장애 주의해야함.
3. 보안
1) 메세지 큐단계에서 보안 적용시 고려해야할 사항
- 프로듀서/컨슈머는 인증을 할 수 있는가?
- 인가된 프로듀서/컨슈머만 메세지를 전달할 수 있는가?
- 저장된 메세지 암호화(메세지 큐 <-> 내구 저장소)
- 브로커들 간에 인증 할 수 있나?
- 통신간 메세지 암호화(브로커간)
4. 장애 허용
장애가 날 것 염두해두고 데이터 유실 가능성 있는 지점 파악해야함.
1) 메세지 큐 단계에서 브로커 사이 발생할 수 있는 장애 3

- ① 브로커에 장애 발생 : 브로커가 내구 저장소에 저장하기 직전에 메모리에 가지고 있던 메세지
- 프로듀서가 브로커로 메세지 보낸 후, 디스크에 저장되었다는 확인 응답(ack) 받기
- 메세지 큐 소프트웨어가 2개 이상의 브로커로 메세지 복제. (2개 이상의 브로커에서 동시에 디스크에 저장하기 직전에 장애 발생 시 동일, 하지만 가능성 희박)
- 브로커가 메세지 처리할 떄 메세지 최대한 작게 가지고있기 -> 안전하지만 처리 속도 하락할 가능성있음.
- ② 브로커 사이 네트워크 장애
- 메세지 큐 소프트웨어들은 최소 1개 이상의 브로커들에 메세지 복제하여 저장하는 기능 있음
- 브로커간 네트워크 장애 발생 이후 복구 후 동기화 하는 기능도 있음. 아래 사항 확인해야
- 새롭게 메세지 복제위해 어떤 브로커가 선택되는지?
- 네트워크 통신이 장애 복구되면 어떻게 동작하는지?
- 네트워크 장애로 판단하기 위해 지연 정도 설정 가능한지?
- 네트워크 장애 이후 복구되지 못하면 어떻게 동작하는지?
- 프로듀서가 클러스터에서 탈락된 브로커에 메세지 보내게 되면 데이터는 어떻게 되는지?
- ③ 저장소에 장애 발생
- 아래 사항 확인하여 메세지 큐 소프트웨어 선택해야함
- 유실된 데이터 복제본 있는지?
- 복제 진행 중 디스크에 기록되지 않은 상태에서 장애 발생 시 데이터 유실되는지?
- 브로커 복구 방법?
- 아래 사항 확인하여 메세지 큐 소프트웨어 선택해야함
5. 비지니스 시나리오에 적용하기
- 수집, 분석 단계에서 네트워크 지연이 발생하면 서비스에 어떤(얼마나) 영향이 가는가?
- 며칠만큼의 데이터가 유실돼도 괜찮은가?
- 며칠만큼의 데이터를 저장해야하는가?
- 스트리밍 시스템의 메세지 전달 시맨틱은 무엇이야 하는가?
4장 스트리밍 데이터 분석
요약
1. 스트리밍 시스템에서는 인플라이트 데이터 기반으로 지속적인 쿼리를 수행한다.
- In-flight : 시스템에서 입력(메세징 큐 단계)과 출력, 클라이언트(다음 단계)를 묶은 시스템에서 활용되는 튜플. 내구 저장소에 영원히 저장되지 않는다.
- Continueous Queries Model : 쿼리 실행되면 데이터가 추가되면서 지속적으로(인터벌/이벤트 트리거로 인해) 데이터가 추출되는 시스템
2. 분산 스트림 프로세싱 아키텍처
원천 데이터 <-> 스트림 프로세서 <-> 스트리밍 매니저 <- 애플리케이션 드라이버
정리 (펼치기)
1. 인플라이트 데이터 분석
1) 인플라이트 데이터와 연속 쿼리
- In-flight : 시스템에서 입력(메세징 큐 단계)과 출력, 클라이언트(다음 단계)를 묶은 시스템에서 활용되는 튜플. 내구 저장소에 영원히 저장되지 않는다.
(<-> Data at rest : 데이터가 중간 저장소나 디스크에 저장된다) - Continueous Queries Model : 쿼리를 하면 데이터가 지속적으로 들어오는 시스템. 새로운 데이터 도착할 때마다 지속적으로 쿼리가 추출하는 데이터가 달라진다.
쿼리 실행되면 데이터가 추가되면서 지속적으로(인터벌/이벤트 트리거로 인해) 데이터가 추출된다. 쿼리로 추출된 데이터는 사용자/애플리케이션이 있는 다음 단계로 푸시된다.
(<-> 전통적인 DBMS(RDBMS, Hadoop, HBase, Cassander..) : 데이터 정지되어있어, 데이터 얻기 위해 쿼리 수행해야함)
2. 분산 스트림 프로세싱 아키텍처
1) 스트림 프로세싱을 지원하는 소프트웨어
: 스파크 스트리밍, 스톰, 플링크, 삼자 ...
2) 이들의 공통점
- 스트리밍 애플리케이션이 실행되고나면 하둡의 맵리듀스 작업과 유사하게 동작한다. 애플리케이션들은 클러스터의 노드들로 전달되어 실행된다.
- 클러스터를 이루는 개별 노드들에서 스트리밍 로직이 실행된다.
- 원천 데이터는 스트리밍 로직의 입력이 된다.
3) 스트리밍 분석 아키텍처

- ① 애플리케이션 드라이버 : 스트리밍 매니저에 잡 등록, 마지막에 결과 수집해 잡의 생명 주기 관리.
- ② 스트리밍 매니저 : 스트리밍 잡을 스트림 프로세서로 보냄. 스트림 프로세서가 필요하는 리소스 제어하거나 요청할 수도(프로세서의 생애주기 관리)
- ③ 스트림 프로세서 : 분석 코드 등 스트리밍 잡이 제출되는 동시에 실행된다.
- ④ 원천 데이터 : 스트리밍 잡을 실행하는데 필요한 데이터의 입력/출력. 프로세싱 완료된 데이터는 드라이버가 데이터를 수집할 수도 / 다른 시스템이 가져가거나 / 다른 잡의 입력으로 활용하도록 저장
3. 스트림 프로세싱 프레임워크의 핵심 기능
스트림 프로세싱 프레임워크 선택 시 고려사항들
1) 메세지 전달 시맨틱
3장 2. 3) (1) 메세지 전달 시맨틱 3 참고.
- 최대 한 번 At-most-once : 복잡도 가장 낮음
- 실패 사례 2
- 메세지 누락 -> 유실
- 스트리밍 처리 프로세서 장애 -> 프로세서 복구까지 메세지 지속적으로 유실 가능
- 실패 사례 2
- 적어도 한 번 At-least-once : 유실 없음. 중복 가능
- 스트리밍 시스템이 스트림 프로세서로 전송된 모든 메세지 정상적으로 전달되었는지 추적. 제대로 처리되지 않았다고 판단하면 재전달(메세지 누락/일정 시간 응답 없으면) -> 스트리밍 잡은 멱등성 있게 동작해야함. 중복 상황 고려해서 설계해야함.
- 정확히 한 번 Exactly-once : 가장 복잡도 높음. 유실, 중복 없음
- 발송된 모든 메세지 정보 보관, 중복된 메세지 탐지해 걸러야함
2) 상태 관리
: 처리중인 메세지가 외부 데이터와 연동되거나 이전에 처리된 메세지 참조하여 처리될 경우 상태(State)를 유지해야함.
(1) 스트림 프로세싱 프레임워크가 제공하는 상태 관리 기능
- 인메모리 : (복잡성, 기능 낮음) 마지막 처리한 결과 데이터를 저장. 마지막으로 추출된 데이터 다시 가져가면 장애 발생해도 복구 가능. 데이터를 추적하지 않는 간다한 작업에 적합
- 복제 기반 쿼리 영구 저장소 : (복잡성, 기능 높음) 다양한 데이터 스트림과 결합해 활용 가능.(5장에서)
3) 장애 허용 설계 Fault Tolerance
(1) 스트리밍 아키텍처에서 스트림 처리 중 장애가 발생할 수 있는 부분
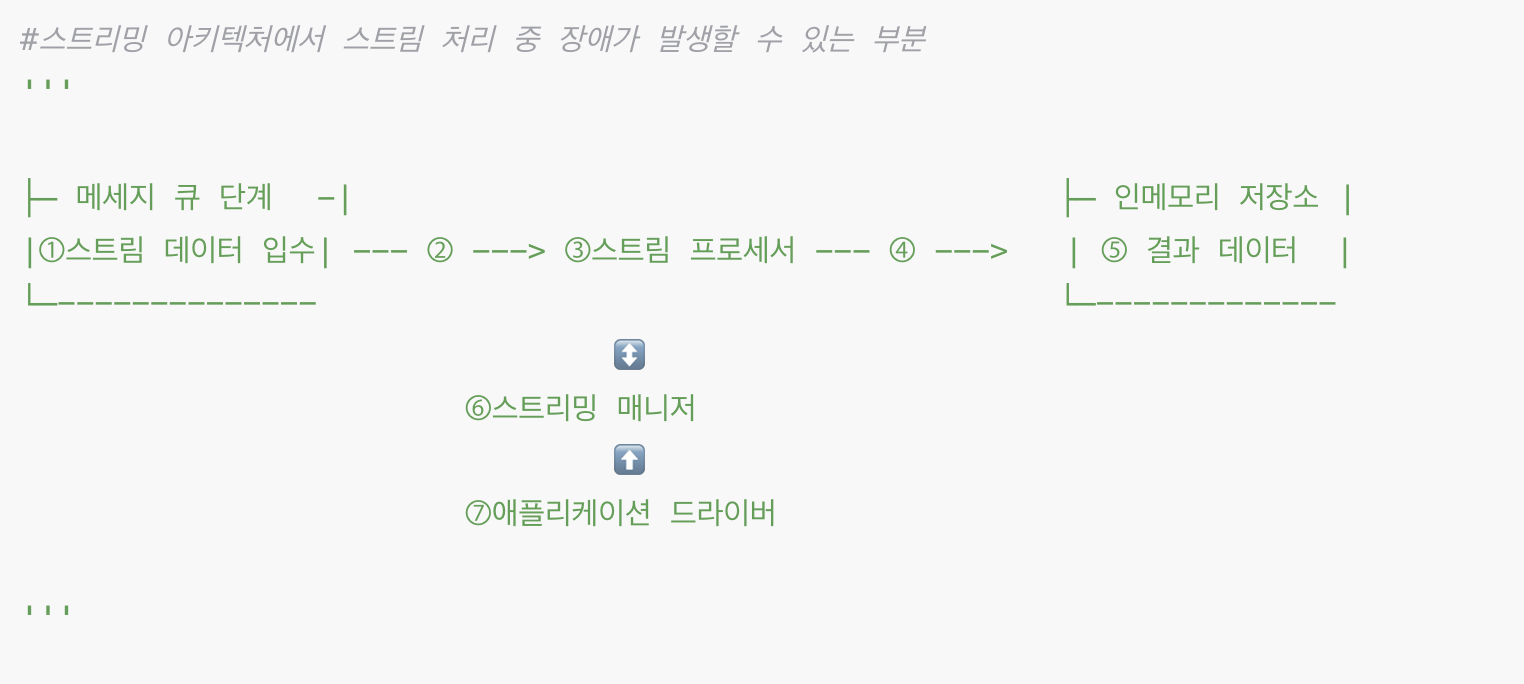
92쪽부터
'Data > Data Engineering & Analystics' 카테고리의 다른 글
| [AWS] RDS Public Access 설정 (0) | 2024.05.18 |
|---|---|
| 데이터 중심 애플리케이션 설계 : 4장 부호화 발전 (0) | 2024.03.31 |
| [Streaming Data 실시간 데이터 파이프라인 아키텍처] 1, 2장 요약 (0) | 2024.03.21 |
| 빅데이터 프레임워크 3주차 - 빅데이터 수집 기술 (0) | 2024.03.21 |
| 빅데이터 프레임워크 2주차 비게이터 기반 기술 - OS 및 가상화 (0) | 2024.03.21 |


